
Hi there, welcome back. Let’s continue talking about Resilience Patterns, and this article is Part - 2 of it. For recalling why we need to care about resilience and how to approach it by following Client-side Load Balancing Pattern, Retries Pattern, and Timeouts Pattern in Microservice Architecture, please refer to Part - 1. We will discuss the following patterns to achieve more resilience:
- Circuit Breakers
- Fallbacks
- Bulkheads
Resilience Pattern-4: Circuit Breakers
Question To Solve
How do you prevent a client from continuing to call a service that’s failing or suffering performance issues? When a service is running slowly, it consumes resources on the client calling it. You want the poorly performed microservices calls to fail fast so that the calling client can quickly respond and take appropriate action.
Common Design
This pattern comes from an electrical circuit breaker. In an electrical system, a circuit breaker will detect whether too much current is flowing through the breaker. Whenever it detects a problem, it will break the connection with the rest of the electrical system and keep the downstream components from being fried. In software technology, when a remote service is called, the circuit breaker will monitor the call. If the calls take too long, the circuit breaker will log the reason and kill the call. In addition, the circuit breaker will also monitor all call failures, and if the number of failures reaches a threshold, the circuit breaker will pop, failing fast and preventing future calls to the failing remote service. And if it is very well-equipped, the circuit breaker will also be in the half-open status to periodically check to see if the remote service being requested is back to normal and re-enable access to it without human intervention.
We could use an LSM (Limited State Machine) to illustrate the transmissions between statuses, as below figure.
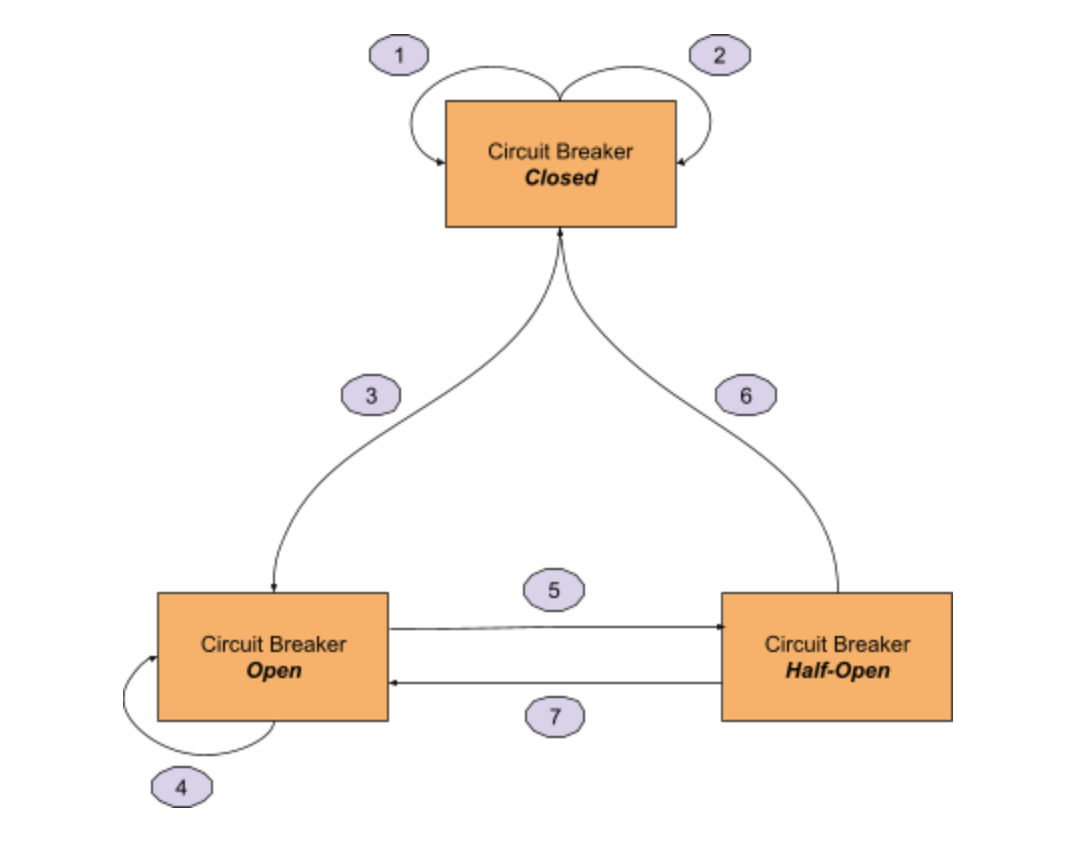
- State - Closed: The circuit breaker is closed, and the target service can be accessed. The circuit breaker maintains a counter of request failures. If it encounters a failed request, the counter will increase 1.
- State - Open: The circuit breaker is open, and the target service can not be accessed. A request to the target service will fail quickly.
- State - Half-Open: The circuit breaker is half-open. It is allowed to try to access the target service. If the request can be accessed successfully, it means that the service is back to normal. Otherwise, the service is still performing poorly.
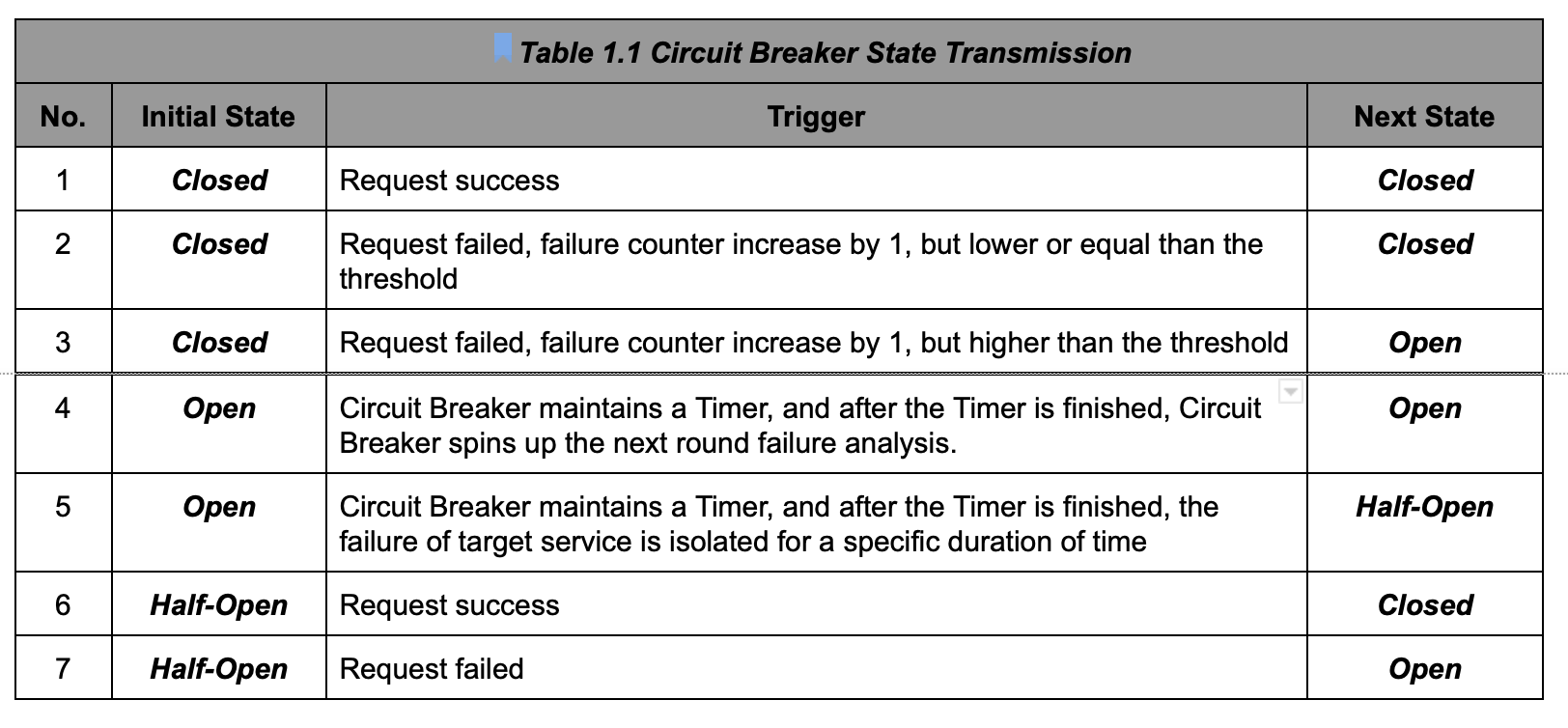
Implementation in AWS App Mesh
App Mesh accomplishes this pattern through the Outlier Detection feature, which can be enabled in the Listener configuration of a specific Virtual Node. Outlier detection applied at the client Envoy allows clients to take near-immediate action on connections with observed known bad failures. It is a form of circuit breaker implementation that tracks the health status of individual hosts in the upstream service. Outlier detection dynamically determines whether endpoints in an upstream cluster are performing unlike the others and removes them from the healthy load balancing set.
Note: As we mentioned in the implementation of Service Discovery, to effectively configure outlier detection for a server Virtual Node, the service discovery method of that Virtual Node should use AWS Cloud Map. Otherwise, if using DNS, the Envoy proxy would only elect a single IP address for routing to the upstream service, nullifying the outlier detection behavior of ejecting an unhealthy host from a set of hosts. Refer to the Service discovery method section for more details on the Envoy proxy's behavior in relation to the service discovery type.
The following four configurations are all required,
- maxServerErrors: Number of consecutive 5xx errors required for ejection, the minimum value of 1, which corresponds to the failure threshold in Step.2 and Step.3 of Circuit Breaker State Transmission. And also, please make sure don’t use the 501 code to mark any business-related unimplemented error.
- maxEjectionPercent: Maximum percentage of hosts in the load balancing pool for upstream service that can be ejected. Will eject at least one host regardless of the value. The minimum value of 0. The maximum value of 100.
- interval: The time interval between ejection sweep analysis, which corresponds to the Step.4 of Circuit Breaker State Transmission.
- baseEjectionDuration: The base amount of time for which a host is ejected, which corresponds to the Step.5 of Circuit Breaker State Transmission.
For example, we could configure the Circuit Breaker for sw-foo-service like below,
- Virtual Node for service normal deployment with 5 maxServerErrors and 10s interval
apiVersion: appmesh.k8s.aws/v1beta2
kind: VirtualNode
metadata:
name: sw-foo-service
namespace: sw-foo-service
spec:
podSelector:
matchLabels:
app: sw-foo-service
listeners:
- portMapping:
port: 8080
protocol: http
healthCheck:
...
timeout:
perRequest:
unit: ms
value: 5000
idle:
unit: s
value: 600
outlierDetection:
maxServerErrors: 5
maxEjectionPercent: 50
interval:
unit: s
value: 10
baseEjectionDuration:
unit: s
value: 10
serviceDiscovery:
awsCloudMap:
namespaceName: foo.prod.softwheel.aws.local
serviceName: sw-foo-service
- Virtual Node for service heavy deployment with fewer maxServerErrors and shorter interval
apiVersion: appmesh.k8s.aws/v1beta2
kind: VirtualNode
metadata:
name: sw-foo-service-heavy
namespace: sw-foo-service
spec:
podSelector:
matchLabels:
app: sw-foo-service
feature: heavy-calculation
listeners:
- portMapping:
port: 8080
protocol: http
healthCheck:
...
timeout:
perRequest:
unit: s
value: 60
idle:
unit: s
value: 600
outlierDetection:
maxServerErrors: 3
maxEjectionPercent: 50
interval:
unit: s
value: 5
baseEjectionDuration:
unit: s
value: 5
serviceDiscovery:
awsCloudMap:
namespaceName: foo.prod.softwheel.aws.local
serviceName: sw-foo-service
attributes:
- key: feature
value: heavy-calculation
Resilience Pattern-5: Fallbacks
Question To Solve
Is there an alternative path that the client can take to retrieve data from or take action when a service call fails?
Common Design
With this pattern, when a remote service call fails, rather than generating an exception, the client service will execute an alternative code path and try to carry out an action through another means. This usually involves looking for data from another data source or queueing the user’s request for future processing. The user’s call will not be shown an exception indicating a problem, but they may be notified that their request will have to be fulfilled at a later time. Fallback could help the system fail gracefully.
For instance, suppose you have an e-commerce website that monitors your user’s behavior and tries to give them recommendations of other items they could buy. Typically, you might call a microservice to run an analysis of the user’s past behavior and return a list of recommendations tailored to that specific user. However, if this preference service fails, your fallback might be to retrieve a more general list of preferences that are based on all user purchases and is much more generalized. This data might come from an entirely different service and data source.
While some Service Mesh failure recovery features improve the reliability and availability of services in the mesh, applications must handle the failure or errors and take appropriate fallback actions. For example, when all instances in a load balancing pool have failed, Sidecar returns an HTTP 503 code. The application must implement any fallback logic needed to handle the HTTP 503 error code. So the Fallbacks pattern is on the application side, which is not able to be controlled by Service Mesh. Therefore, we won’t have a section to talk about the implementation in AWS App Mesh.
Resilience Pattern-6: Bulkheads
Question To Solve
How do you segregate different service calls on a client to make sure one misbehaving service does not consume all the resources on the client side? How do you limit the requests rate or connections rate to a given service?
Common Design
This pattern emerged from the concept of building ships. With a bulkhead design, a ship is divided into completely segregated and watertight compartments called bulkheads. Even if the ship’s hull is punctured, because the ship is divided into watertight compartments (bulkheads), the bulkhead will keep the water confined to the area of the ship where the puncture occurred and prevent the entire ship from filling with water and sinking.
The same concept can be applied to a service that must interact with multiple remote resources. By using the Bulkhead pattern, you can break the calls to remote resources into their own thread pools and reduce the risk that a problem with one slow remote resource call will take down the entire application. The thread pools act as the bulkheads for your service. Each remote resource is segregated and assigned to the thread pool. If one service is responding slowly, the thread pool for that one type of service call will become saturated and stop processing requests. Service calls to other services won’t become saturated because they’re assigned to other thread pools.
Implementation in AWS App Mesh
App Mesh accomplishes this pattern through the Connection Pool feature, which can be enabled in the Listener configuration of a specific Virtual Node. Connection pooling limits the number of connections that an Envoy can concurrently establish with all the hosts in the upstream cluster. It is intended to protect your local application from being overwhelmed with connections and lets you adjust traffic shaping for the needs of your applications. You can configure destination-side connection pool settings for a virtual node listener. App Mesh sets the client-side connection pool settings to infinite by default, simplifying mesh configuration.
- For HTTP listener, we could specify two configurations for controlling the connection pool:
– maxConnections: Maximum number of outbound TCP connections Envoy can establish concurrently with all hosts in the upstream cluster, the minimum value of 1. This is required.– maxPendingRequests: Number of overflowing requests after maxConnections Envoy will queue to the upstream cluster, the minimum value of 1. The default value is 2147483647. - For HTTP/2 and gRPC listener, we only need to specify one configuration for controlling the pool
– maxRequests: Maximum number of inflight requests Envoy can concurrently support across hosts in the upstream cluster, the minimum value of 1.
For example, we could configure the Connection Pool for sw-foo-service like this,
- Virtual Node for service normal deployment with 50 maxConnections and 20 maxPendingRequests
apiVersion: appmesh.k8s.aws/v1beta2
kind: VirtualNode
metadata:
name: sw-foo-service
namespace: sw-foo-service
spec:
podSelector:
matchLabels:
app: sw-foo-service
listeners:
- portMapping:
port: 8080
protocol: http
healthCheck:
...
timeout:
perRequest:
unit: ms
value: 5000
idle:
unit: s
value: 600
outlierDetection:
maxServerErrors: 5
maxEjectionPercent: 50
interval:
unit: s
value: 10
baseEjectionDuration:
unit: s
value: 10
connectionPool:
http:
maxConnections: 50
maxPendingRequests: 20
serviceDiscovery:
awsCloudMap:
namespaceName: foo.prod.softwheel.aws.local
serviceName: sw-foo-service
- Virtual Node for service heavy deployment with fewer maxConnections and maxPendingRequests
apiVersion: appmesh.k8s.aws/v1beta2
kind: VirtualNode
metadata:
name: sw-foo-service-heavy
namespace: sw-foo-service
spec:
podSelector:
matchLabels:
app: sw-foo-service
feature: heavy-calculation
listeners:
- portMapping:
port: 8080
protocol: http
healthCheck:
...
timeout:
perRequest:
unit: s
value: 60
idle:
unit: s
value: 600
outlierDetection:
maxServerErrors: 3
maxEjectionPercent: 50
interval:
unit: s
value: 5
baseEjectionDuration:
unit: s
value: 5
connectionPool:
http:
maxConnections: 20
maxPendingRequests: 5
serviceDiscovery:
awsCloudMap:
namespaceName: foo.prod.softwheel.aws.local
serviceName: sw-foo-service
attributes:
- key: feature
value: heavy-calculation
Wrap Up
We wrote two blogs to talk about how to leverage Resilience Patterns to build a fault-tolerant and high available Microservice Architecture. In total, we introduced the below 6 patterns by breaking them down to what are they, how to solve them, and how to implement the solution in AWS App Mesh:
- Client-side Load Balancing Pattern
- Retries Pattern
- Timeouts Pattern
- Circuit Breakers Pattern
- Fallbacks Pattern
- Bulkheads Pattern
For the next article in the Microservice Governance series, I will show you how to leverage some Deployment Patterns to build a robust and highly scalable production environment for hosting thousands of microservices. See you later.



